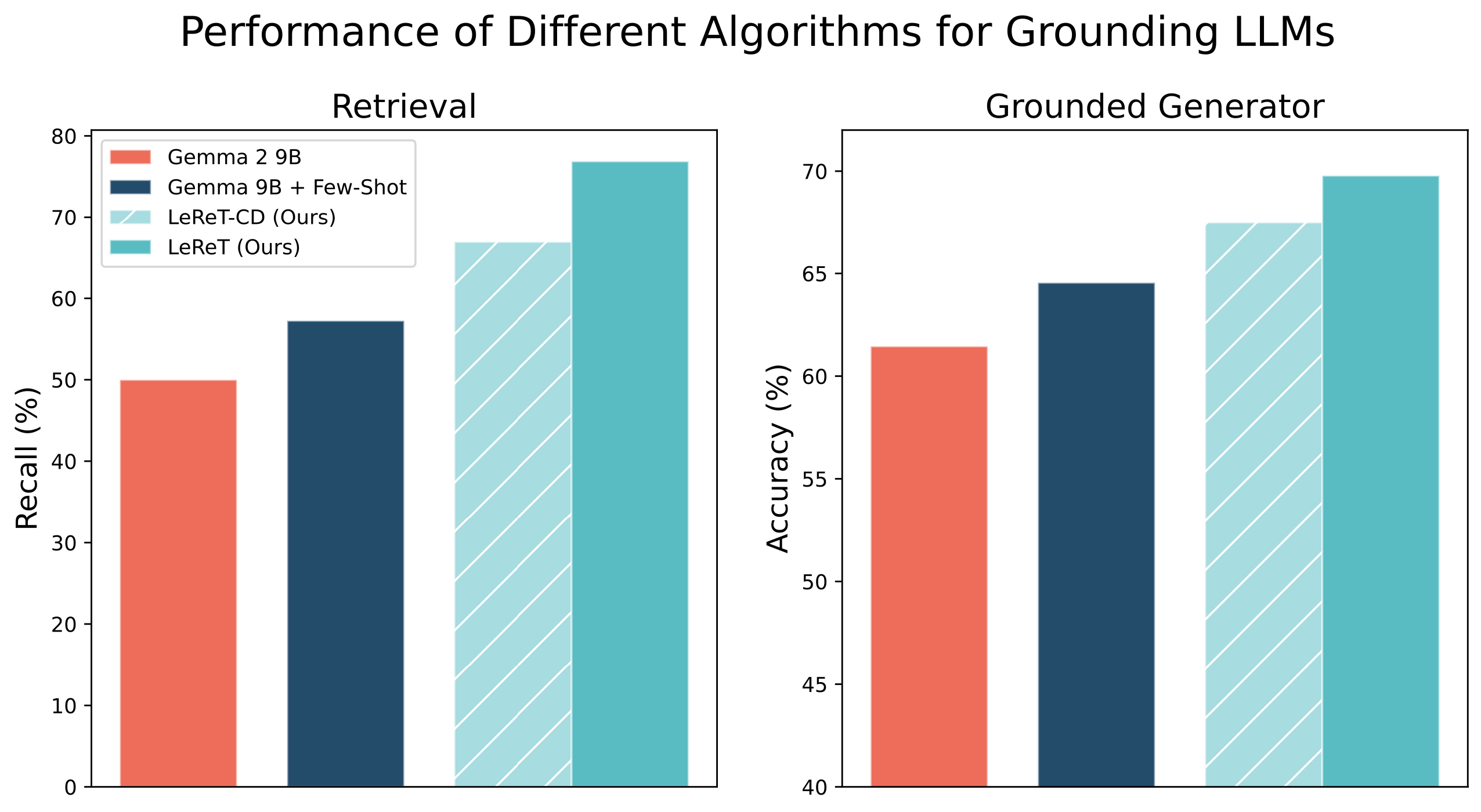
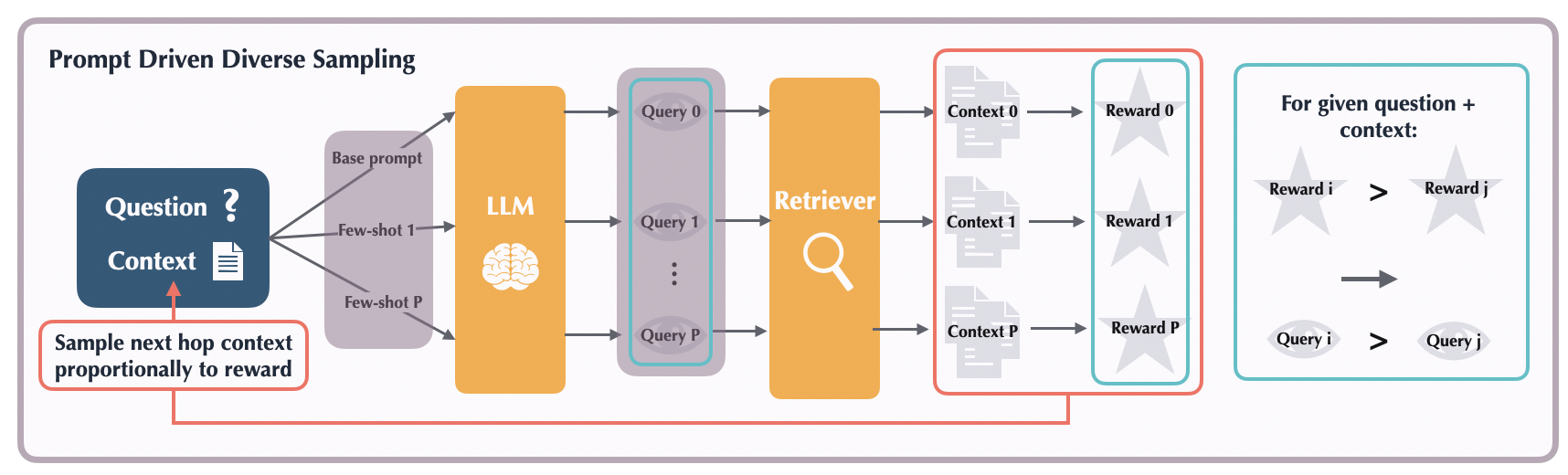
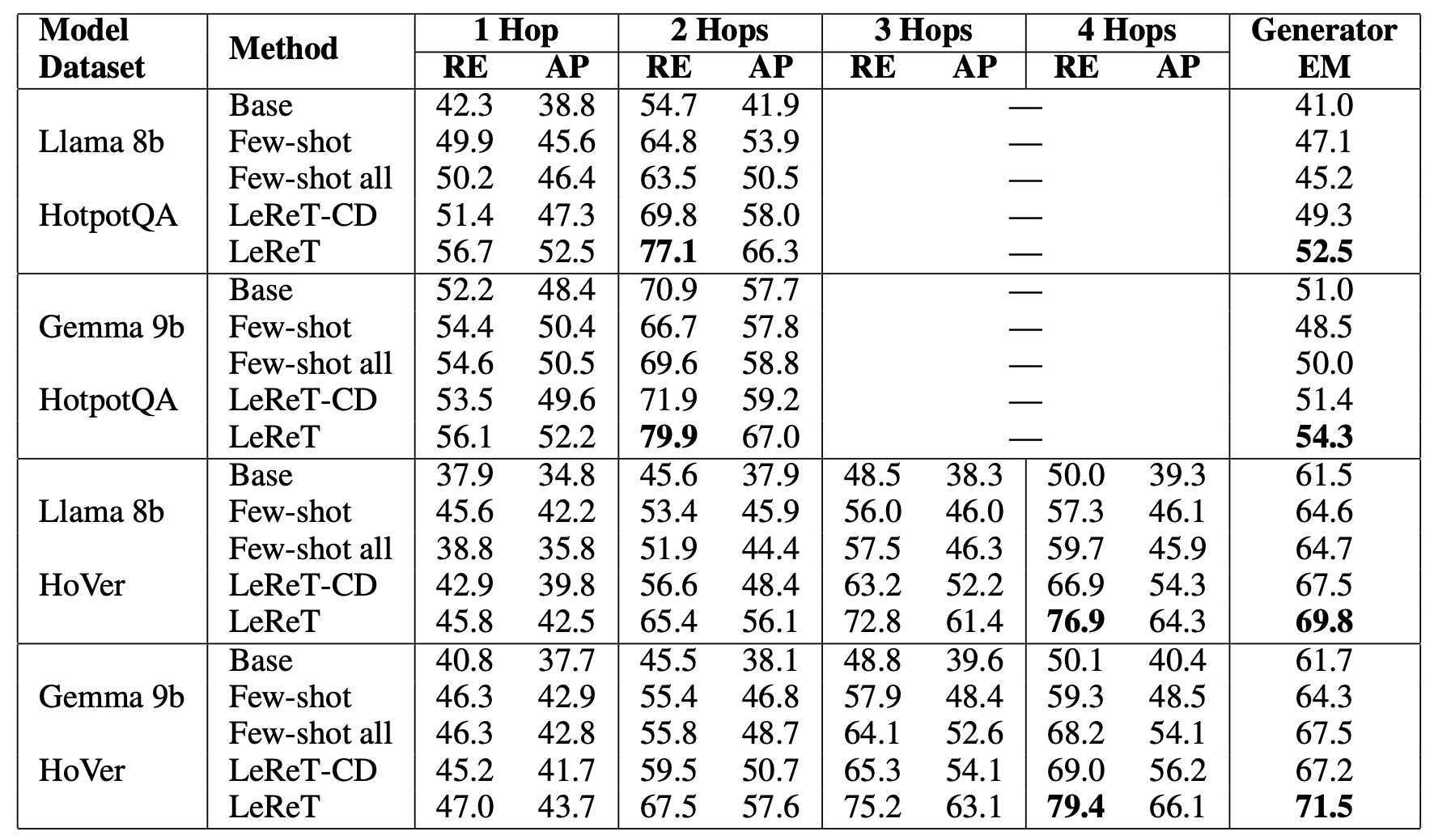
Mitigating hallucinations is a prerequisite for trusting answers generated by large language models (LLMs) that are prone to making convincing but inaccurate claims. Grounding the answers in data generated and verified by humans provides a natural avenue for improving the reliability of LLMs. However, it can be hard to capture relevant facts for user questions based on just the semantic similarity, especially as questions becomes more complex and the relevant facts become more indirect. What if LLMs could query for relevant facts based on the user question? While this can enable retrieving relevant but indirect facts, zero-shot performance of instruction-tuned LLMs leaves more to be desired and generating supervision on how to retrieve relevant facts can be expensive and retriever dependent. Our key insight is that LLMs can learn to retrieve relevant facts by different queries, learning to upweight queries that result in relevant facts. This leads to our reinforcement learning based framework, Learning to Retrieve by Trying ( LeReT), where the LLM generates queries for multi-hop retrieval and uses preference-based reinforcement learning to improve the LLM queries. Our experimental results demonstrate that LeReT can improve the absolute retrieval accuracy by up to 29% and the downstream generator evaluations by 17%. The simplicity and flexibility of LeReT allows it to be applied to arbitrary retrievers, and makes it a promising technique for improving general LLM pipelines.
@misc{hsu2024groundingtryingllmsreinforcement,
title={Grounding by Trying: LLMs with Reinforcement Learning-Enhanced Retrieval},
author={Sheryl Hsu and Omar Khattab and Chelsea Finn and Archit Sharma},
year={2024}
}